📚 Module and FragmentHierarchy of computing points in the Thinker™ is inherently limited to tree-like structure. More complex calculations can be done with typical functions wrapped into reusable shells, called "modules".
Instantiation of a module, called "fragment", is another sort of a shell. While a module describes what is included inside it, a fragment describes how this particular instance of the module is connected with other fragments. It also contains a set of specific parameters which are applied to customize the module. This concept has a direct analogy between fragment-module pair and call-procedure pair used in programming languages. Every parameter propagates deep into hierarchy but it can be re-defined at any embedded fragment.
A fragment can reference few types of modules. Most important is a computing module. It is built of computing points. Another type of module is a so-called "field". Simply put, it is a one-to-one interlink for network data, to perform elementary transitional operations over the data, to implement data generators or data agents for external data suppliers and consumers, and so on, as defined by attached Java class. By default, a field provides a trivial passthrough channel for every pin, letting to join data networks together.
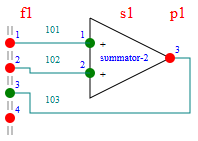
While runtime network represents a very simple structure, a project network provides more convenient ways to describe data flows. It defines a "pin" - a mapping from a runtime channel. That has a property to indicate data flow direction, in or out. Another optional property maps a pin to computing point. The last one has a similar optional property to link to specific pin. Pins can be grouped into so called "joints". It helps to organize data channels of similar meaning under a single definition and simplify documentation. When a model is prepared for runtime, joints of fragments are connected to joints of modules, to provide connectivity across a whole hierarchy. | Sections
Order
Tutorials
|
 A module can contain one or more hierarchies of computing points. It can include other modules as well,
provided that embedded modules don’t create a module reference loop. This way a complex regular computing
structure can be defined in a very compact form, because every instance of embedded module is just a
parameterized reference (link) rather than its copy.
A module can contain one or more hierarchies of computing points. It can include other modules as well,
provided that embedded modules don’t create a module reference loop. This way a complex regular computing
structure can be defined in a very compact form, because every instance of embedded module is just a
parameterized reference (link) rather than its copy. Each fragment, that references the same module name, receives its own copy of a module contents at runtime,
thus all modules of the same type appear distinct in the model and so don’t exhibit their own computed data. It
opens an opportunity to use stateful classes in calculations. However, it requires a computer to provide more
memory to hold so called "flat" runtime model. Such approach looks similar to projects of integrated circuits
but differentiates it from computer software concepts.
Each fragment, that references the same module name, receives its own copy of a module contents at runtime,
thus all modules of the same type appear distinct in the model and so don’t exhibit their own computed data. It
opens an opportunity to use stateful classes in calculations. However, it requires a computer to provide more
memory to hold so called "flat" runtime model. Such approach looks similar to projects of integrated circuits
but differentiates it from computer software concepts.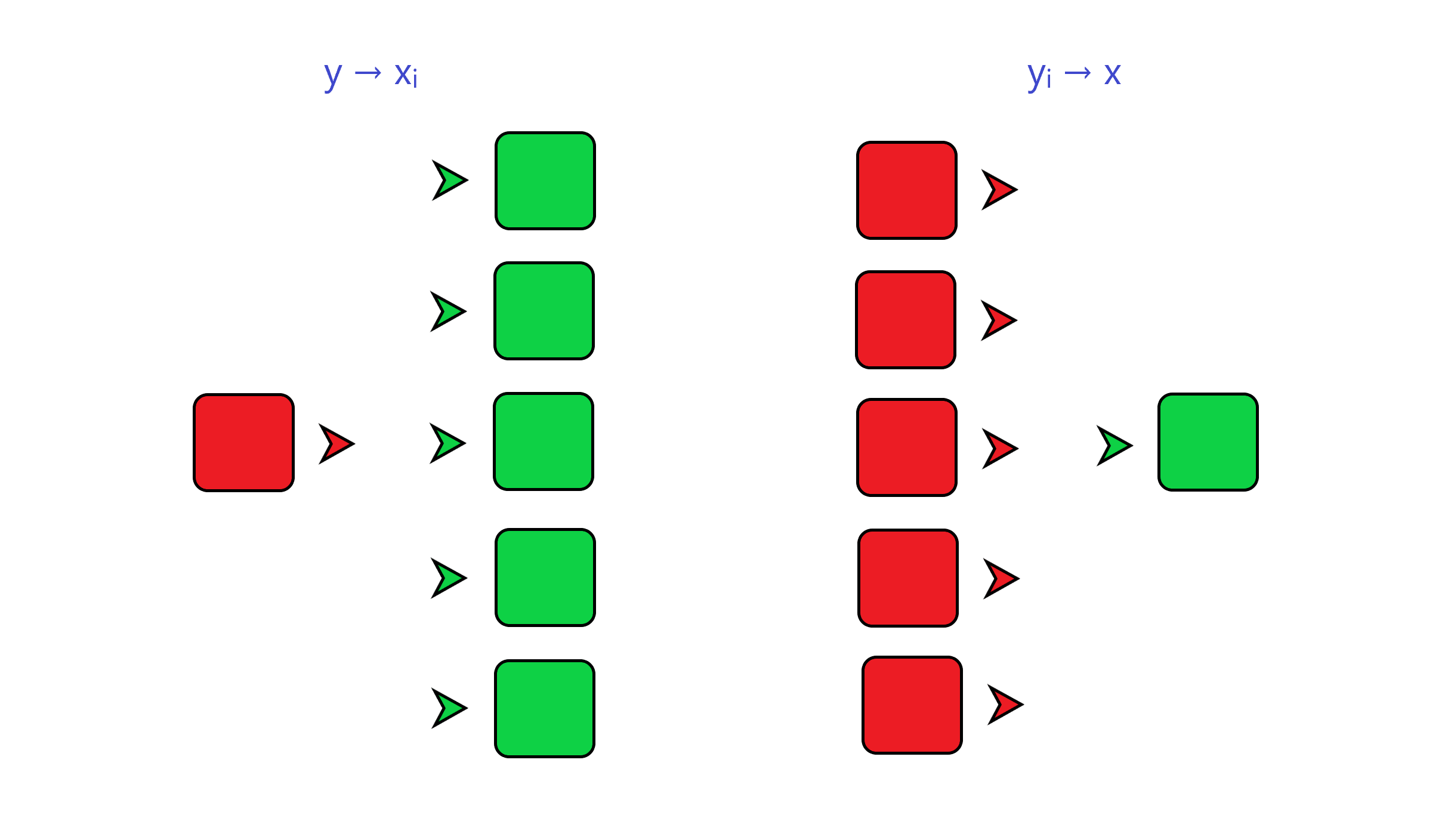 As every piece of the project in fact appears as a sort of module, every module and every fragment provide
a solution to establish data flows in and out. There are two types of data flow gates in runtime model, commonly
named as a "channel": a "transmitter" to supply computed value outside, and a "receiver" to acquire value inside. Their
connections form a network where data circulate. There are no strict restrictions for the net. It can contain many
transmitters and many receivers. Network operates by a single rule: every transmitter sends its value to every
receiver within network. It demands for receiver to have as low latency as possible.
As every piece of the project in fact appears as a sort of module, every module and every fragment provide
a solution to establish data flows in and out. There are two types of data flow gates in runtime model, commonly
named as a "channel": a "transmitter" to supply computed value outside, and a "receiver" to acquire value inside. Their
connections form a network where data circulate. There are no strict restrictions for the net. It can contain many
transmitters and many receivers. Network operates by a single rule: every transmitter sends its value to every
receiver within network. It demands for receiver to have as low latency as possible.